AutoRA (Automated Research Assistant) is an open-source framework designed to automate various stages of empirical research, including model discovery, experimental design, and data collection.
This notebook is the first of four notebooks within the basic tutorials of autora. We suggest that you go through these notebooks in order as each builds upon the last. However, each notebook is self-contained and so there is no need to run the content of the last notebook for your current notebook.
These notebooks provide a comprehensive introduction to the capabilities of autora. It demonstrates the fundamental components of autora, and how they can be combined to facilitate automated (closed-loop) empirical research through synthetic experiments.
How to use this notebook You can progress through the notebook section by section or directly navigate to specific sections. If you choose the latter, it is recommended to execute all cells in the notebook initially, allowing you to easily rerun the cells in each section later without issues.
Installation¶
The AutoRA ecosystem is a comprehensive collection of packages that together establish a framework for closed-loop empirical research. At the core of this framework is the autora package, which serves as the parent package and is essential for end users to install. It provides functionalities for automating workflows in empirical research and includes vetted modules with minimal dependencies.
However, the flexibility of autora extends further with the inclusion of optional modules as additional dependencies. Users have the freedom to selectively install these modules based on their specific needs and preferences.
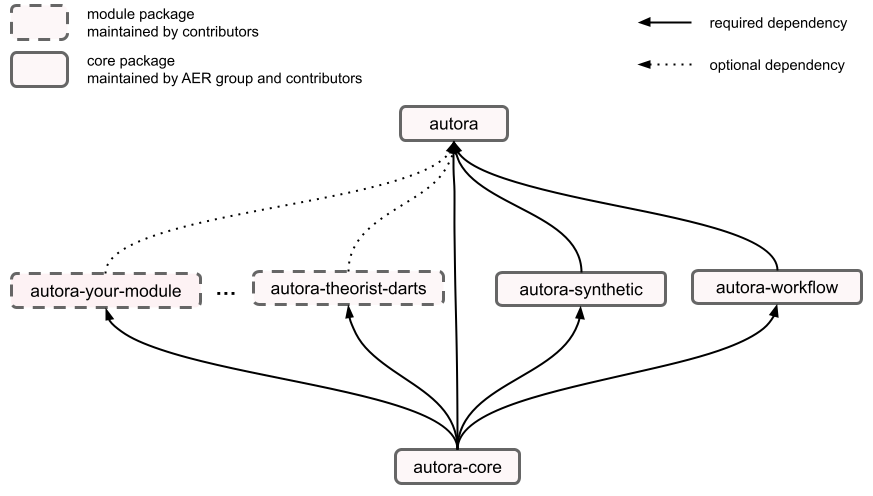
Optional dependencies enable users to customize their autora environment without worrying about conflicts with other packages within the broader autora ecosystem. To install an optional module, simply use the command pip install autora[dependency-name], where dependency-name corresponds to the name of the desired module (see example below).
To begin, we will install all the relevant optional dependencies. Our main focus will be on two experimentalists: experimentalist-falsification and experimentalist-novelty, along with a Bayesian Machine Scientist (BMS) implemented in the theorist-bms package. It's important to note that installing a module will automatically include the main autora package, as well as any required dependencies for workflow management and running synthetic experiments.
!pip install -q "autora[experimentalist-falsification]"
!pip install -q "autora[experimentalist-novelty]"
!pip install -q "autora[theorist-bms]"
WARNING: typer 0.12.3 does not provide the extra 'all' WARNING: typer 0.12.3 does not provide the extra 'all' WARNING: typer 0.12.3 does not provide the extra 'all'
To make all simulations in this notebook replicable, we will set some seeds.
import numpy as np
import torch
np.random.seed(42)
torch.manual_seed(42)
<torch._C.Generator at 0x1f2aa767710>
Automated Empirical Research Components¶
The goal of this section is to set up all autora components to enable a closed-loop discovery workflow with synthetic data. This involves specifying (1) the experiment runner, (2) a theorist for model discovery, (3) an experimentalist for identifying novel experiment conditions.
- Experiment Runner: A component that takes in conditions and collects corresponding observations.
- Theorist: A component that takes in the full collection of conditions and observations and outputs models that link the two.
- Experimentalist: A component that outputs new conditions, which are intended to yield novel observations.

Each of these components automates a process of the scientific method that is generally conducted manually. The experiment runner parallels a research assistant that collects data from participants. The theorist takes the place of a computational scientist that applies modelling techniques to discover how to best describe the data. The experimentalist acts as a research design expert to determine the next iteration of experimentation. Each of these steps in the scientific method can be arduous and time consuming to conduct manually, and so autora allows for the automation of these steps and thus quickens the scientific method by leveraging data-driven techniques.
Toy Example of the Components¶
Before jumping into each component in detail, we will present a toy example to provide you with an overview on how these components work together within a closed-loop. After some setup, you will see steps 1-3, which uses the three components - namely, the experimentalist to propose new conditions, the experiment runner to retrieve new observations from those conditions, and the theorist to model the new data. We then finish this example by plotting our data and findings.
#Setup: Import modules
import matplotlib.pyplot as plt
from autora.theorist.bms import BMSRegressor
from autora.experimentalist.random import random_sample #Note that this sampler is embedded within the autora-core module and so does not need to be explicitly installed
#Step 0: Defining variables
ground_truth = lambda x: np.sin(x) #Define a ground truth model that we will attempt to recover - here a sine wave
initial_X = np.linspace(0, 4 * np.pi, 200) #Define initial data
#Step 1: EXPERIMENTALIST: Sample using the experimentalist
new_conditions = random_sample(initial_X, num_samples=30)
new_conditions = np.array(new_conditions).reshape(-1,1) #Turn variable into a 2D array
#Step 2: EXPERIMENT RUNNER: Define and then obtain observations using the experiment runner
run_experiment = lambda x: ground_truth(x) + np.random.normal(0, 0.1, size=x.shape) #Define the runner, which here is simply the ground truth with noise
new_observations = run_experiment(new_conditions) #Obtain observations from the runner for the conditions proposed by the experimentalist
new_observations = new_observations.reshape(-1,1) #Turn variable into a 2D array
#Step 3: THEORIST: Initiate and fit a model using the theorist
theorist_bms = BMSRegressor(epochs=100) #Initiate the BMS theorist
theorist_bms.fit(new_conditions, new_observations) #Fit a model to the data
#Wrap-Up: Plot data and model
sort_index = np.argsort(new_conditions, axis=0)[:,0] #We will first sort our data
new_conditions = new_conditions[sort_index,:]
new_observations = new_observations[sort_index,:]
plt.plot(initial_X, ground_truth(initial_X), label='Ground Truth')
plt.plot(new_conditions, new_observations, 'o', label='Sampled Conditions')
plt.plot(initial_X, theorist_bms.predict(initial_X.reshape(-1,1)), label=f'Bayesian Machine Scientist ({theorist_bms.repr()})')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Sine Function')
plt.legend()
INFO:autora.theorist.bms.regressor:BMS fitting started 100%|██████████| 100/100 [00:04<00:00, 24.88it/s] INFO:autora.theorist.bms.regressor:BMS fitting finished
<matplotlib.legend.Legend at 0x1f2d6a4a1a0>

Do not stop with this toy example! At this point, it may be tempting to start working on your own project, but we urge you to continue through the tutorials. autora has a lot of embedded functionality that you are going to want to use, and this toy example has stripped those away. So, keep going and see how much autora has to offer!
Experiment Runners¶
autora provides support for experiment runners, which serve as interfaces for conducting both real-world and synthetic experiments. An experiment runner typically accepts experiment conditions as input (e.g., a 2-dimensional numpy array with columns representing different independent variables) and produces collected observations as output (e.g., a 2-dimensional numpy array with columns representing different dependent variables). These experiment runners can be combined with other autora components to facilitate closed-loop scientific discovery.
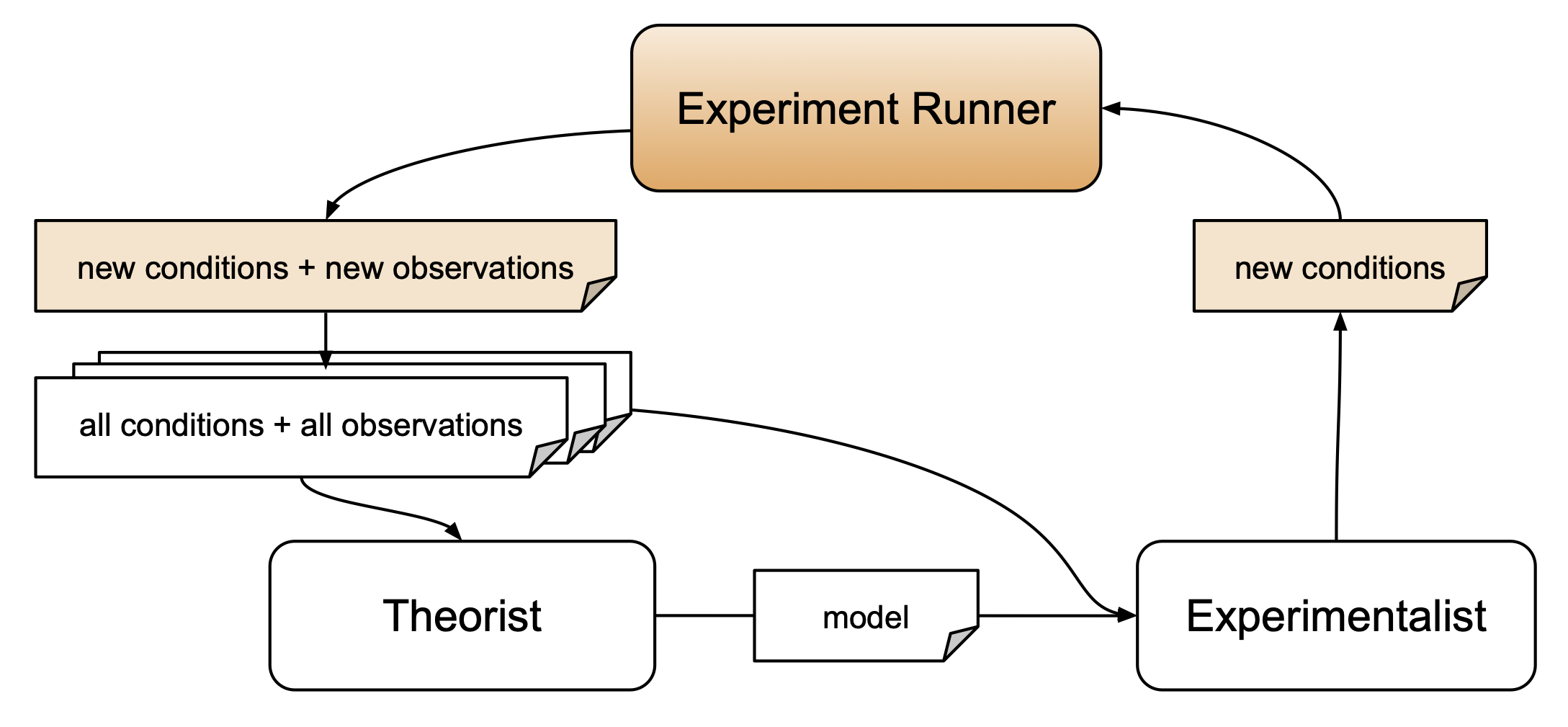
Types¶
autora offers two types of experiment runners: real-world experiments and synthetic experiments.
For real-world experiments, experiment runners can include interfaces for various scenarios such as web-based experiments for behavioral data collection (e.g., using Firebase and Prolific) or experiments involving electrical circuits (e.g., using Tinkerforge). These runners often require external components such as databases to store collected observations or servers to host the experiments. You may refer to the respective tutorials for these interfaces on how to set up all required components.
Synthetic experiments are conducted on synthetic experiment runners, which are functions that take experimental conditions as input and generate simulated observations as output. These experiments serve multiple purposes, including testing autora components before applying them to real-world experiments, benchmarking methods for automated scientific discovery, or conducting computational metascientific experiments.
In this introductory tutorial, we primarily focus on simple synthetic experiments. For more complex synthetic experiments implementing various scientific models, you can utilize the autora-synthetic module.
Usage¶
To create a synthetic experiment runner, we begin with defining a ground truth from which to generate data. Here, we consider a simple sine function:
$y = f(x) = \sin(x)$
In this case, $x$ corresponds to an independent variable (the variable we can manipulate in an experiment), $y$ corresponds to a dependent variable (the variable we can observe after conducting the experiment), and $f(x)$ is the ground-truth function (or "mechanism") that we seek to uncover via a combination of experimentation and model discovery.
However, we assume that observations are obtained with a measurement error when running the experiment.
$\hat{y} = \hat{f}(x) = f(x) + \epsilon, \quad \epsilon \sim \mathcal{N}(0,0.1)$
where $\epsilon$ is the measurement error sampled from a normal distribution with $0$ mean and a standard deviation of $0.1$.
The following code block defines the ground truth $f(x)$ and the experiment runner $\hat{f}(x)$ as lambda functions.
ground_truth = lambda x: np.sin(x)
run_experiment = lambda x: ground_truth(x) + np.random.normal(0, 0.1, size=x.shape)
Next, we generate a pool of all possible experimental conditions from the domain $[0, 2\pi]$.
condition_pool = np.linspace(0, 2 * np.pi, 100)
In order to run a simple synthetic experiment, we can first sample from the pool of possible experiment conditions (without replacement), and then pass these conditions to the synthetic experiment runner:
initial_conditions = np.random.choice(condition_pool, size=10, replace=False)
initial_observations = run_experiment(initial_conditions)
# plot sampled conditions against ground-truth
plt.plot(condition_pool, ground_truth(condition_pool), label='Ground Truth')
plt.plot(initial_conditions, initial_observations, 'o', label='Sampled Conditions')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Sine Function')
plt.legend()
<matplotlib.legend.Legend at 0x1f28b43a200>

Certain theorists and experimentalists may need to have knowledge about the experimental variables, such as the domain from which new experiment conditions are sampled. To provide this information, we can utilize a VariableCollection object, which contains immutable metadata about dependent variables, independent variables, and covariates. In the context of our synthetic experiment, we have a single independent variable (iv) denoted as $x$, and a single dependent variable (dv) denoted as $y$.
from autora.variable import Variable, ValueType, VariableCollection
# Specify independent variable
iv = Variable(
name="x", # name of the independent variable
value_range=(0, 2 * np.pi), # specify the domain
allowed_values=condition_pool, # alternatively, we can specify the pool of allowed conditions directly
)
# specify dependent variable
dv = Variable(
name="y", # name of the dependent variable
type=ValueType.REAL, # specify the variable type (some theorists require this to optimize)
)
# Variable collection with ivs and dvs
variables = VariableCollection(
independent_variables=[iv],
dependent_variables=[dv],
)
Note: For expository reasons, we focus in this tutorial on simple synthetic experiments. In general, autora provides functionality for automating more complex synthetic experiments, as well as real-world experiments, such as behavioral data collection via web-based experiments, experiments with electrical circuits via Tinkerforge, and other automated experimentation platforms.
Theorists¶
The autora framework includes and interfaces with different methods for scientific model discovery. These methods are referred to as theorists and are implemented as sklearn estimators. For general information about theorists, see the respective AutoRA Documentation.
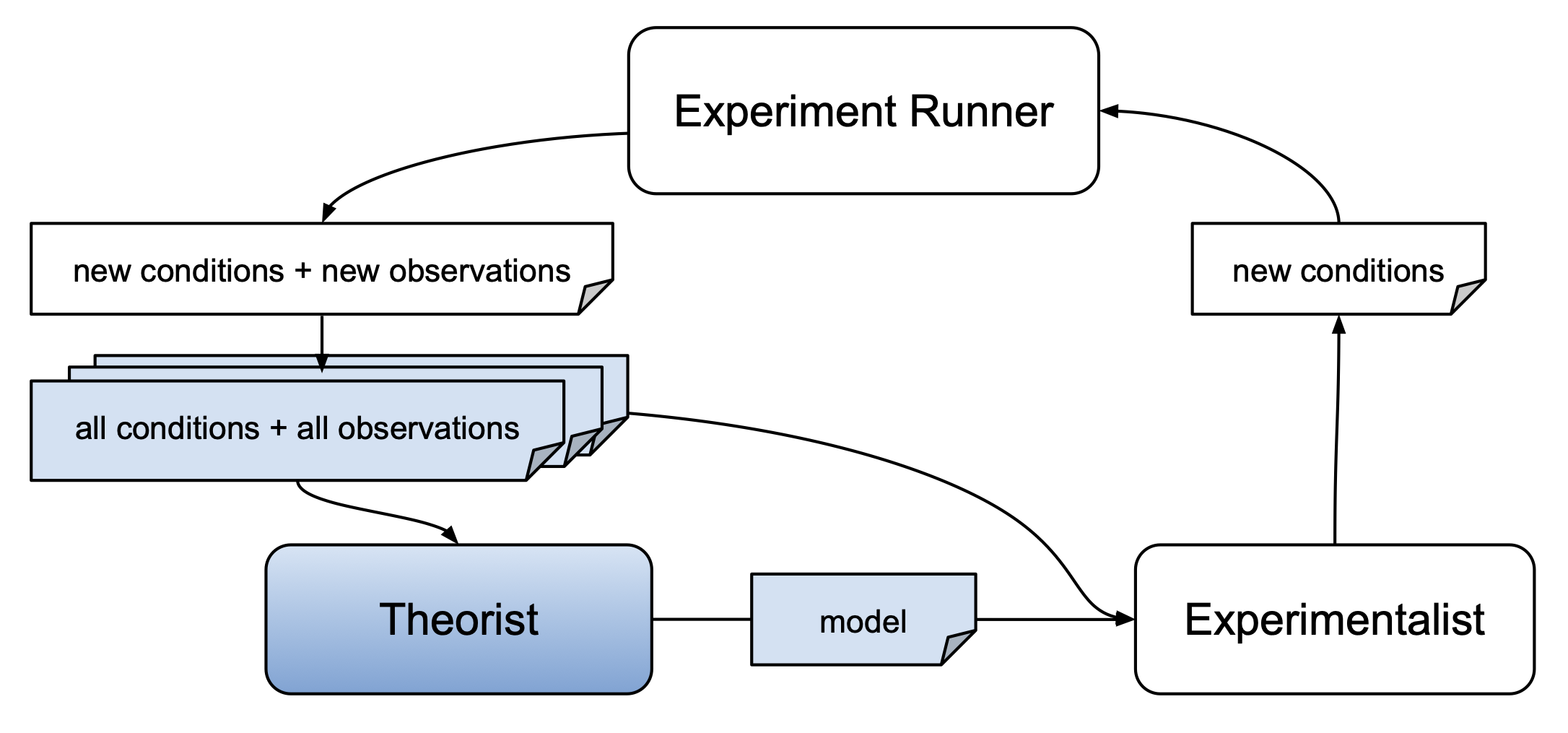
Theorists take as input a set of conditions and observations. Conditions and observations can typically be passed as two-dimensional numpy arrays (with columns corresponding to variables and rows corresponding to different instances of those variables). Theorists then identify and fit a model which may be used to predict observations based on experiment conditions.
Types¶
There are different types of theorists within the AutoRA framework, each with its own approach to scientific model discovery.
Some theorists focus on fitting the parameters of a pre-specified model to the given data (see the scikit learn documentation for a selection of basic regressors). The model architecture in such cases is typically fixed, while the parameters are adjusted to optimize the model's performance. Linear regression is an example of a parameter-fitting theorist.
Other theorists are concerned with identifying both the architecture of a model and its parameters. The model architectures can take various forms, such as equations, causal models, or process models. Implemented as scikit-learn estimators, these theorists aim to discover a model architecture that accurately describes the data. They often operate within a user-defined search space, which specifies the allowable operations or components that can be included in the model. This approach provides more flexibility in exploring different model architectures.
Usage¶
In this tutorial, we delve into two types of theorists: (1) a linear regression theorist, which focuses on fitting a linear model, and (2) a Bayesian Machine Scientist (Guimerà et al., 2020, in Science Advances), which specializes in identifying and fitting a non-linear equation.
Theorists are commonly instantiated as regressors within the sklearn library:
from sklearn.linear_model import LinearRegression
from autora.theorist.bms import BMSRegressor
theorist_lr = LinearRegression()
theorist_bms = BMSRegressor(epochs=100)
Once instantiated, we can fit the theorist to link experimental conditions with observations. However, before doing so, we should convert both inputs into 2-dimensional numpy arrays. Theorists should return a single model directly or multiple models within a list.
# convert data to 2-dimensional numpy array
initial_conditions = initial_conditions.reshape(-1, 1)
initial_observations = initial_observations.reshape(-1, 1)
print(f"Size of the initial conditions: {initial_conditions.shape},\nSize of the initial observations: {initial_observations.shape}\n")
# fit theorists
theorist_lr.fit(initial_conditions, initial_observations)
theorist_bms.fit(initial_conditions, initial_observations)
INFO:autora.theorist.bms.regressor:BMS fitting started
Size of the initial conditions: (10, 1), Size of the initial observations: (10, 1)
100%|██████████| 100/100 [00:04<00:00, 22.11it/s] INFO:autora.theorist.bms.regressor:BMS fitting finished
sin(X0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
sin(X0)
For some theorists, we can inspect the resulting model architecture. For instance, in the BMS theorist, we can obtain the model formula via theorist_bms.repr().
print(f"Model of BMS theorist: {theorist_bms.repr()}")
Model of BMS theorist: sin(X0)
We may now obtain predictions from both theorists for the entire pool of experiment conditions.
# convert condition pool into 2-dimensional numpy array before generating respective predictions
condition_pool = condition_pool.reshape(-1, 1)
# obtain predictions
predicted_observations_lr = theorist_lr.predict(condition_pool)
predicted_observations_bms = theorist_bms.predict(condition_pool)
In the next code segment, we plot the theorists' predictions against the ground truth. For the BMS theorist, we can obtain a latex expression of the model architecture using theorist_bms.latex().
# obtain latex expression of BMS theorist
bms_model = theorist_bms.latex()
# plot model predictions against ground-truth
import matplotlib.pyplot as plt
plt.plot(condition_pool, ground_truth(condition_pool), label='Ground Truth')
plt.plot(initial_conditions, initial_observations, 'o', label='Data Used for Model Identification')
plt.plot(condition_pool, predicted_observations_lr, label='Linear Regression')
plt.plot(condition_pool, predicted_observations_bms, label='Bayesian Machine Scientist: $' + bms_model + '$')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Model Predictions')
plt.legend()
<matplotlib.legend.Legend at 0x1f2b0a78c40>

Note: There are various other types of theorists you can combine with AutoRA as long as they are implemented as sklearn estimators. This includes autora modules, any scikit learn estimators, as well as third-party packages, such as PySR for symbolic regression.
Experimentalists¶
The primary goal of an experimentalist is to design experiments that yield scientific merit. The autora framework offers various strategies for identifying informative new data points (e.g., by searching for experiment conditions that existing scientific models fail to explain, or by looking for novel conditions altogether).
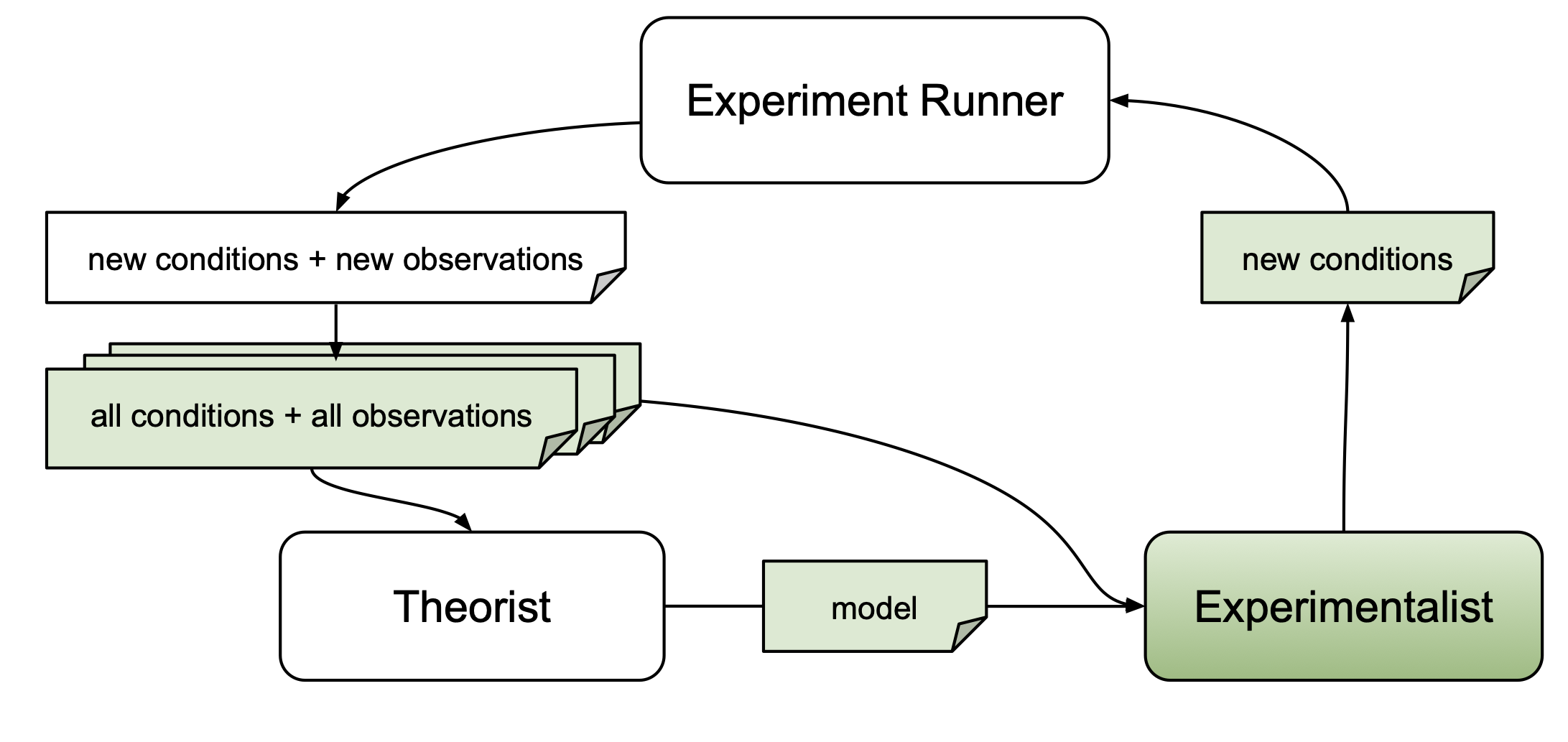
Experimentalists are implemented as functions that return a set of experiment conditions (e.g., in the form of a 2-dimensional numpy array in which columns correspond to independent variables), which can be subjected to an experiment. To determine these conditions, experimentalists may use information about candidate models obtained from a theorist, experimental conditions that have already been probed, or respective dependent measures. For more detailed information about experimentalists, please refer to the corresponding AutoRA Documentation.
Types¶
There are generally two types of experimentalist functions: poolers and samplers.
Poolers generate a novel set of experimental conditions "from scratch", e.g., by sampling from a grid. They usually require metadata describing independent variables of the experiment (e.g., their range or the set of allowed values).
Samplers operate on an existing pool of experimental conditions. They typically require experimental conditions to be represented as a 2-dimensional numpy array in which columns correspond to independent variables and rows to different conditions. They then select experiment conditions from this pool.
Usage: Poolers¶
Experimentalist poolers are implemented as functions and can be called directly. For instance, the following grid pooler generates a grid based on the allowed_values of all independent variables in the metadata object that we defined above. We can simply add a list of allowed values to each independent variable. In this case, we only have one variable.
allowed_values = np.linspace(0, 2 * np.pi, 100)
variables.independent_variables[0].allowed_values = allowed_values
Now we can pass the grid pooler the list of independent variables from the variables object.
from autora.experimentalist.grid import grid_pool
new_conditions = grid_pool(variables=variables)
The resulting condition pool contains all experiment conditions from the grid:
# return first 10 conditions
for idx, condition in enumerate(new_conditions.values):
print(condition)
if idx > 9:
break
[0.] [0.06346652] [0.12693304] [0.19039955] [0.25386607] [0.31733259] [0.38079911] [0.44426563] [0.50773215] [0.57119866] [0.63466518]
Alternatively, we may use the random pooler to randomly draw experimental conditions from the domains of each independent variable. The random pooler requires as input a list of discrete values from which to sample from. In this case, we can pass it variables for the independent variable. We can also specify the input argument num_samples to obtain 10 random samples.
from autora.experimentalist.random import random_pool
# generate random pool of 10 conditions
num_samples = 10
new_conditions = random_pool(variables=variables,
num_samples=num_samples)
# print conditions
for idx, condition in enumerate(new_conditions.values):
print(condition)
[1.90399555] [4.75998887] [4.31572324] [0.57119866] [5.58505361] [4.82345539] [2.53866073] [2.0943951] [4.06185717] [3.87145761]
Usage: Samplers¶
An experiment sampler typically requires an existing pool of conditions as input along with additional arguments. For instance, the novelty sampler requires, aside from a pool of conditions, a list of prior conditions. The user may also specify the number of samples num_samples to select from the pool.
The novelty sampler will then select novel experiment conditions from the pool which are most dissimilar to some reference conditions, such as the initial_conditions obtained above:
from autora.experimentalist.novelty import novelty_sample
new_conditions_novelty = novelty_sample(conditions = condition_pool,
reference_conditions = initial_conditions,
num_samples = 2)
print(new_conditions_novelty)
0 36 2.284795 37 2.348261
Another example for an experiment sampler is the falsification sampler. The falsification sampler identifies experiment conditions under which the loss of a candidate model (returned by the theorist) is predicted to be the highest. This loss is approximated with a neural network, which is trained to predict the loss of the candidate model, given some initial experimental conditions, respective initial observations, and the variables.
The following code segment calls on the falsification sampler to return novel conditions based on the candidate model of the linear regression theorist introduced above. As with the novelty sampler, we seek to select 2 conditions.
from autora.experimentalist.falsification import falsification_sample
new_conditions_falsification = falsification_sample(
conditions=condition_pool,
model=theorist_lr,
reference_conditions=initial_conditions,
reference_observations=initial_observations,
metadata=variables,
num_samples=2
)
print(new_conditions_falsification)
[[6.28318531] [6.21971879]]
We can plot the selected conditions for both samples relative to the selected samples. Since we don't have observations for those conditions, we plot them as vertical lines.
type(new_conditions_novelty)
pandas.core.frame.DataFrame
# plot model predictions against ground-truth
y_min = np.min(initial_observations)
y_max = np.max(initial_observations)
# plot conditions obtained by novelty sampler
for idx, condition in enumerate(new_conditions_novelty):
if idx == 0:
plt.plot([condition, condition], [y_min, y_max], '--r', label='novelty conditions')
else: # we want to omit the label for all other conditions
plt.plot([condition, condition], [y_min, y_max], '--r')
# plot conditions obtained by falsification sampler
for idx, condition in enumerate(new_conditions_falsification):
if idx == 0:
plt.plot([condition[0], condition[0]], [y_min, y_max], '--g', label='falsification conditions')
else: # we want to omit the label for all other conditions
plt.plot([condition[0], condition[0]], [y_min, y_max], '--g')
plt.plot(condition_pool, ground_truth(condition_pool), '-', label='Ground Truth')
plt.plot(initial_conditions, initial_observations, 'o', label='Initial Data')
plt.plot(condition_pool, predicted_observations_lr, '-k', label='Prediction from Linear Regression')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Sampled Experimental Conditions')
plt.legend()
<matplotlib.legend.Legend at 0x1f2daefbe80>

Next Notebook¶
After defining all the components required for the empirical research process, we can create an automated workflow using basic loop constructs. The next notebook, AutoRA Basic Tutorial II: Loop Constructs, illustrates the use of these loop constructs.