Basic Tutorial Ib: Experimentalists¶
Experimentalists are functions designed to return novel experimental conditions that yield scientific merit.
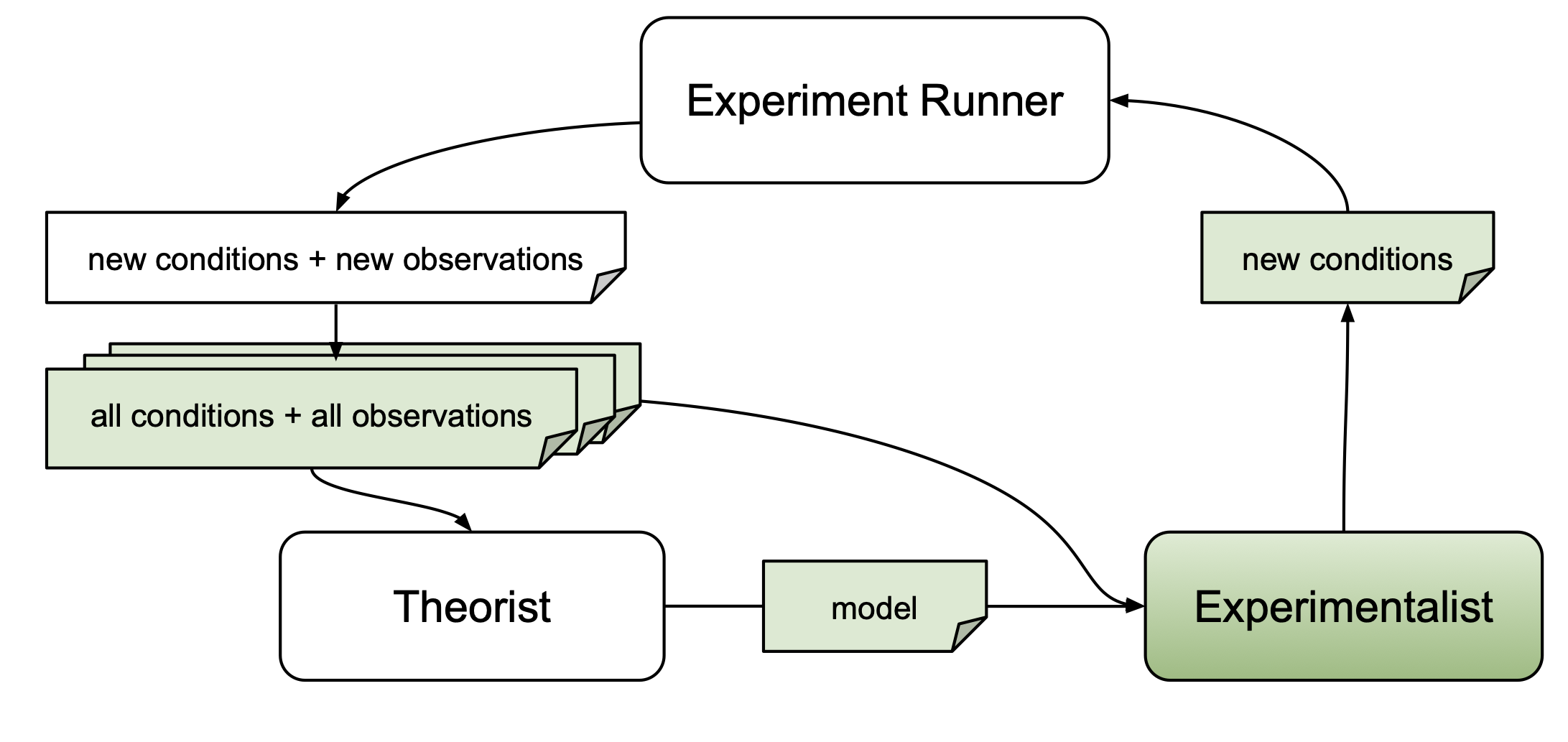
Experimentalists may use information about candidate models $M$ obtained from a theorist, experiment conditions that have already been probed $\vec{x}' \in X'$, or respective dependent measures $\vec{y}' \in Y'$.
The following tutorial demonstrates how to use a falsification experimentalist referred to as falsification sampler. The falsification sampler identifies experiment conditions under which the loss $\hat{\mathcal{L}}(M,X,Y,\vec{x})$ of the best candidate model is predicted to be the highest. This loss is approximated with a multi-layer perceptron, which is trained to predict the loss of a candidate model, $M$, given experiment conditions $X$ and dependent measures $Y$ that have already been probed.
We begin with importing the relevant packages.
# Uncomment the following line when running on Google Colab
# !pip install "autora[experimentalist-falsification]"
import numpy as np
from sklearn.linear_model import LinearRegression
from autora.variable import DV, IV, ValueType, VariableCollection
from autora.experimentalist.falsification import falsification_sample, falsification_score_sample
In order to reproduce our results, we also import torch and set the seed.
import torch
torch.manual_seed(180)
np.random.seed(180)
Example 1: Sampling From A Sine Function¶
In this example, we will consider a dataset resembling the sine function. We will then fit a linear model to the data and use the falsification sampler to identify experiment conditions under which the model is predicted to perform the worst.
First, we define the experiment conditions $X$ and the observations $Y$. We consider a domain of $X \in [0, 2\pi]$, and sample 100 data points from this domain.
X = np.linspace(0, 2 * np.pi, 100)
Y = np.sin(X)
Next, we need to define metadata object, so the falsification sampler knows what data it is supposed to generate. We can do this by defining the independent variable $x$, which underlies experimental conditions $X$, and the dependent variable $y$, which underlies the observations $Y$. We specify that $x$ is a continuous variable with a range of $[0, 2\pi]$, and $y$ is a real-valued variable.
# Specify independent variable
iv = IV(
name="x",
value_range=(0, 2 * np.pi),
)
# specify dependent variable
dv = DV(
name="y",
type=ValueType.REAL,
)
# Variable collection with ivs and dvs
metadata = VariableCollection(
independent_variables=[iv],
dependent_variables=[dv],
)
Next, we can specify the model that we would like to fit to the data. In this case, we will use a linear model.
model = LinearRegression()
model.fit(X.reshape(-1, 1), Y)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| fit_intercept | True | |
| copy_X | True | |
| tol | 1e-06 | |
| n_jobs | None | |
| positive | False |
Finally, we can generate novel experimental conditions $X'$ from the falsification sampler. We will select 5 novel experimental conditions from a candidate set of 14 experiment conditions.
X_prime = np.linspace(0, 6.5, 14)
new_conditions = falsification_sample(
conditions=X_prime,
model=model,
reference_conditions=X,
reference_observations=Y,
metadata=metadata,
num_samples=5,
plot=True,
)



Before we examine the novel conditions, let's have a look at the three plots generated by the falsification sampler, going from last to first.
Model Prediction vs. Data. The model trained on the data is shown in red, and the model prediction is shown in blue. The model prediction is a straight line, which is a poor fit to the data. This is expected, since the data is generated from a sine function, which is not linear.
Loss of the Falsification Network. The plot shows the learning curve for the falsification network that is trained to predict the error of the (linear) model as a function of experimental conditions. The error (loss) of this network decreases as a function of the number of training epochs.
Prediction of Falsification Experimentalist. The plot shows the predicted loss of the model as a function of the experimental condition. The model is predicted to perform the worst at the extremes of the domain, which is expected since the model is a poor fit to the data. The red dots show the true loss of the model at the corresponding experimental condition. The predicted loss is a good approximation of the true loss.
The falsification sampler will identify novel experimental conditions that maximize the predicted loss (shown as a blue line in the plot "Prediction of Falsification Experimentalist").
Before examining the selected new conditions, we need to convert them to a numpy array.
new_conditions = new_conditions.to_numpy()
print(new_conditions)
[[0. ] [6.5] [6. ] [2. ] [4. ]]
Note that the new conditions are all at the limits of the domain $\{0, 2\pi\}$, as well as around the peaks of the sinusoid, which is expected since the model is a poor fit to the data at those points. We can also plot the new conditions on top of the data.
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(X, Y, c="r", label="Old Data")
ax.scatter(new_conditions, np.zeros_like(new_conditions), c="g", label="New Experimental Conditions")
ax.plot(X, model.predict(X.reshape(-1, 1)), c="b", label="Model Prediction")
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.legend()
<matplotlib.legend.Legend at 0x732bfc69fd10>

We can also obtain "falsification" scores for the sampled experiment conditions using ``falsification_score_sample''. The scores are z-scored with respect to all conditions from the candidate set. In the following example, we sample 5 conditions and return their falsification scores.
scores_df = falsification_score_sample(
conditions=X_prime,
model=model,
reference_conditions=X,
reference_observations=Y,
metadata=metadata,
num_samples=5,
)
new_conditions = np.asarray(X_prime)[scores_df.index]
scores = scores_df['score'].to_numpy()
print(new_conditions)
print(scores)
[0. 0.5 1. 1.5 2. ] [2.634674 1.864585 0.15935703 0.14204112 0.10674001]
Example 2: Sampling From A Gaussian Mixture Model¶
In this example, we will consider a dataset sampled from a Gaussian mixture model. We will fit a Gaussian mixture model to the data and use the falsification sampler to identify experiment conditions under which the model is predicted to perform the worst.
First, we define the experimental conditions $X$ and the observations $Y$, and sample 100 data points. The dependent variable is a categorical variable with 2 categories.
from sklearn.datasets import make_blobs
X, Y = make_blobs(n_samples=100, n_features=1, centers=2, random_state=0)
Next, we need to define metadata object, so the falsification sampler knows what data it is supposed to generate. We can do this by defining the independent variable $x$ underlying the experimental conditions $X$ and the dependent variable $y$ underlying the observations $Y$ as "VariableCollection" objects. We specify that $X$ is a continuous variable with a range of $[-1, 6]$, and $Y$ is a categorical variable.
# Specify independent variable
iv = IV(
name="X",
value_range=(-1, 6),
)
# specify dependent variable
dv = DV(
name="Y",
type=ValueType.CLASS,
)
# Variable collection with ivs and dvs
metadata = VariableCollection(
independent_variables=[iv],
dependent_variables=[dv],
)
Next, we can specify the model that we would like to fit to the data. In this case, we will use a Gaussian mixture model with 2 components.
from sklearn.mixture import GaussianMixture
model = GaussianMixture(n_components=2, random_state=2)
model.fit(X, Y)
# plot model fit against data
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(X, Y, c="r", label="Data")
ax.scatter(X, model.predict(X), c="b", label="Model Prediction")
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.legend()
<matplotlib.legend.Legend at 0x732bfc5941a0>

In this case, the model appears to predict most of the data points quite well but fails to predict data points around $x=3$. Let's see if the falsification sampler can identify this region of the domain. We will select samples from a candidate set of 71 experiment conditions.
X_prime = np.linspace(-1, 6, 71)
and call the falsification sampler.
new_conditions = falsification_sample(
conditions=X_prime,
model=model,
reference_conditions=X,
reference_observations=Y,
metadata=metadata,
num_samples=10,
plot=True,
)



As shown in the "Prediction of Falsification Network" plot, the model is predicted to perform the worst around $x=3$. Let's have a look at the selected new conditions.
new_conditions = new_conditions.to_numpy()
print(new_conditions)
[[2.9] [3.2] [3.3] [2.5] [2.6] [2.8] [2.4] [2.7] [2.3] [2.2]]
Indeed, the new conditions mostly located around $x=3$, reflecting a poor fit of the model for those conditions. Finally, we can plot the new conditions on top of the data.
fig, ax = plt.subplots()
ax.scatter(X, Y, c="r", label="Data")
ax.scatter(new_conditions, np.zeros_like(new_conditions), c="b", label="New Experimental Conditions")
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.legend()
<matplotlib.legend.Legend at 0x732bfc449190>

Note that in this example the new experimental conditions are concentrated around x ≈ 3, near the model’s decision boundary. This is expected, since the falsification strategy targets regions where the current model is most likely to misclassify or show high prediction error. We can plot these new conditions alongside the original data and the model’s predictions.
fig, ax = plt.subplots()
ax.scatter(X, Y, c="r", label="Old Data")
ax.scatter(new_conditions, np.zeros_like(new_conditions), c="g", label="New Experimental Conditions")
ax.plot(X, model.predict(X.reshape(-1, 1)), c="b", label="Model Prediction")
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.legend()
<matplotlib.legend.Legend at 0x732bfc388da0>

We can also obtain "falsification" scores for the sampled experiment conditions using ``falsification_score_sample''. The scores are z-scored with respect to all conditions from the candidate set. In the following example, we sample 5 conditions and return their falsification scores.
scores_df = falsification_score_sample(
conditions=X_prime,
model=model,
reference_conditions=X,
reference_observations=Y,
metadata=metadata,
num_samples=5,
)
scored_conditions = np.asarray(X_prime)[scores_df.index]
scores = scores_df["score"].to_numpy()
print(scored_conditions)
print(scores)
[-1. -0.9 -0.8 -0.7 -0.6] [1.6834128 1.6422206 1.5483896 1.4479377 1.2526897]